In the rapidly evolving landscape of AI-powered applications, delivering a seamless user experience isn’t just about what you build—it’s about how you deliver it.
Today, I’ll share how we implemented LLM response streaming in Next.js, a challenge that reshaped the way our users engage with AI-driven responses.
Picture this: A user sends a message to your AI chatbot.
Instead of staring at a loading spinner for a long time, they can see the response display word by word, making the conversation feel more engaging and dynamic.
The Challenge
While our backend services using LLMs generate accurate responses, users often grew impatient waiting for complete answers.
The real technical challenge wasn’t just about streaming text, it was about maintaining structured JSON data to support charts and tables generation, all while ensuring the interface stayed responsive and engaging.
Partial JSON Parsing
We found partial-json, a library that solved our JSON streaming puzzle.
This allowed us to handle incomplete JSON structures gracefully, turning a potential technical nightmare into a smooth user experience.
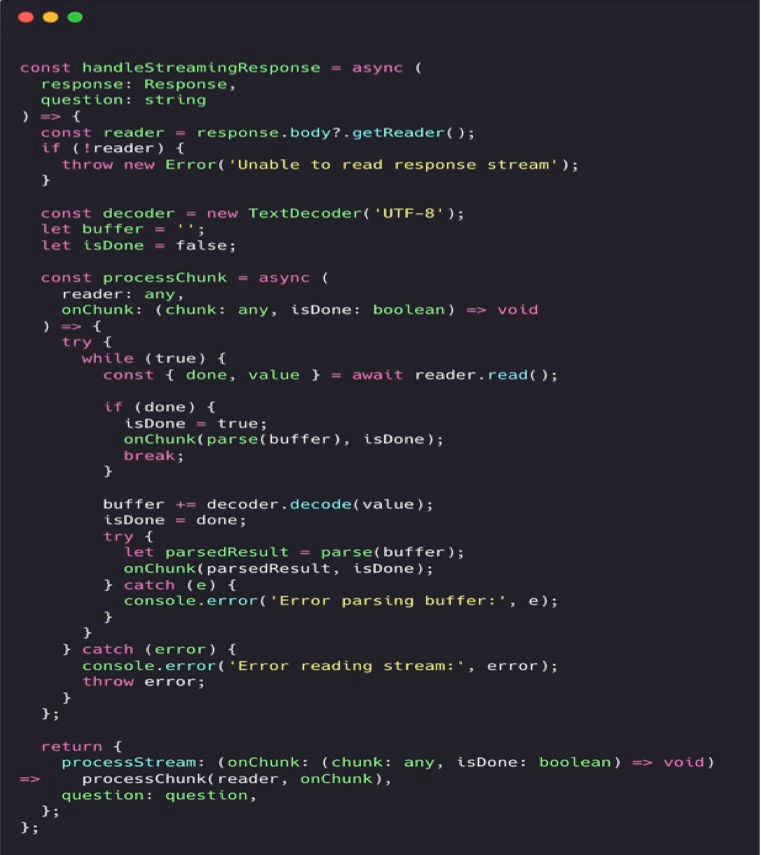
The Solution
Let me share the core implementation of our streaming functionality:
1. Seamlessly Decode Incoming Streams

The decoding process relies on several key mechanisms:
- TextDecoder converts raw binary data into readable text.
- Each chunk is processed as it arrives, ensuring smooth data flow.
- The buffer accumulates decoded text to handle partial messages.
If we don’t use UTF-8 encoding, streaming chunk by chunk can lead to issues.
Without proper encoding, the response might be displayed all at once instead of gradually, disrupting the intended streaming experience.
2. Managing Partial JSON Data

The partial JSON handling is crucial because:
- Traditional JSON.parse() would fail on incomplete structures.
- The parse() function (from partial-json) can handle incomplete JSON.
3. Memory Efficiency

Memory efficiency is achieved through:
- Processing one chunk at a time.
- Not storing the entire response in memory.
- Clearing the buffer after successful parsing.
- Using streaming instead of buffering the whole response.
4. Real-time Feedback
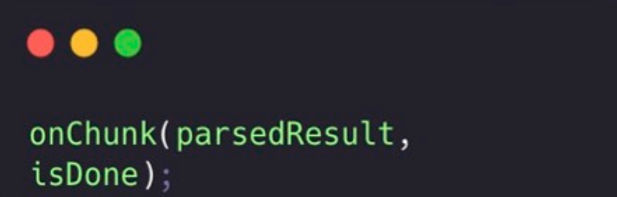
The real-time feedback system:
- Immediately processes each chunk as it arrives.
- Notifies the UI layer through the onChunk callback.
- Includes a completion flag (isDone).
- Allows for progressive UI updates.
Putting It All Together
Here’s how this works together in a typical flow:
- Stream starts.
- Reader is initialized.
- Decoder is prepared.
- Buffer is emptied.
- For each chunk:
- Data is read from the stream.
- Chunk is decoded to text.
- Added to buffer.
- Attempted parsing.
- UI is updated if parsing succeeds.
- Stream ends.
- Final chunk is processed.
- Buffer is cleared.
- Completion is signaled.
- Resources are cleaned up.
Ready to Implement?
Here are three key tips from our experience:
- Always implement timeout mechanisms—streams shouldn’t hang indefinitely.
- Build robust error handling—network issues are inevitable.
- Monitor your buffer management—memory usage can creep up with large responses.
Remember, the goal isn’t just to stream data—it’s to create an experience that makes AI feel more natural and accessible to your users.
Would you like to share your experiences with LLM streaming? Have you faced similar challenges?
Let’s continue this conversation in the comments below.


